-
시작하기 전에
- xlsx2dbc :: hsl's tsmaster 사용기에서 xlsx 파일을 dbc 파일로 변환하는 방법을 설명했다.
- xlsx를 dbc로 변환한다는 것은, dbc를 변환한 xlsx가 존재하는 것을 전제한다. 수작업으로 신호 하나하나 메시지 하나하나 엑셀에서 작업했을 수도 있다. dbc에서 xlsx로 변환하는 파이썬 스크립트를 작성한다.
개요
- 메시지 정의에 필요한 데이터는 무엇인가?
- 신호 정의에 필요한 데이터는 무엇인가?
- dbc2xlsx.py
메시지 정의에 필요한 데이터는 무엇인가?
- xlsx2dbc :: hsl's tsmaster 사용기에 H사가 만든 xlsx를 보면 메시지와 신호를 정의하는데 필요한 최소 데이터를 알 수 있다. 다시 나열하며 아래와 같다.
- Message: 메시지 이름
- ID: 메시지 아이디
- DLC [byte]: 메시지 길이
- Cycle Time [msec]: 전송 주기
- Signal: 시그날(신호) 이름
- Start Bit: 신호 시작 비트 위치
- Length [bit]: 신호 길이. 비트
- Byte Order: Intel 방식 (little endian) 혹은 Motorola (big endian) 방식. H사는 LSB, MSB라고 한다. (상세는 dbc 파일에서 바이트 오더와 스타트 비트 위치와 LSB :: hsl's tsmaster 사용기를 참조하십시오.)
- Value Type: Signed, Unsigned, Float, Double
- Initial Value: 초기값
- Factor, Offset: phy = hex * Factor + Offset. phy: 물리량, hex: 변수의 헥스값 ( CAN 트레이스 보기 - 바퀴 속도 :: hsl's tsmaster 사용기에서 글의 2/3 지점 인근에 있는 "dbc를 불러온 후 트레이스를 보면" 부분을 참조하십시오.)
- Minimum, Maximum:최소값과 최대값
- Unit: 신호의 단위
- Value Table: 0:off, 1:on 같이 키:밸류 관계표
- Comment: 커멘트
- ECU_1, ECU_2: 송수신 관계 표시. T, TX: 송신, R, Rx: 수신
- 녹색은 메시지 정의에 필요하다. 파란색은 신호를 정의할 때 필요하다.
- CANdb++ GUI에서 메시지를 정의할 때 필요한 항목들을 알 수 있다. 아래 그림은 CANdb++에서 메시지를 더블 클릭하면 열리는 메시지 설정창이다.

메시지를 정의하는 창의 Definition 탭이다. - Definition 탭을 보면
- Name: 메시지 이름
- Type:
- CAN Template을 사용한 경우: CAN Standard, CAN Extended
- CAN FD Template을 사용한 경우: CAN Standard, CAN Extended, CAN FD Standard, CAN FD Extended
- ID: 아이디
- DLC: Data Length Code [byte]
- Transmitter: 메시지를 전송하는 제어기. 비활성화 되어있다. 설정하는 방법이 몇 가지있다. Transmitters (복수)탭에서 추가할 수 있다.
- Tx Method: 메시지 전송 방법. 주기적으로 전송되는 메시지의 경우 Cyclic이다. 비활성화 되어있다.
- Cycle Time: 메시지 전송 주기. 비활성화 되어있다. 나는 dbc 파일을 텍스트 에디터에서 열어서 "MsgCycleTime"으로 검색한다. 아래 형식의 줄들이 검새된다.
BA_ "GenMsgCycleTime" BO_ [아이디 10진수] [주기]
-
- 아이디가 맞는지 확인하고 주기를 바꾼다. CAN dbc 편집 :: hsl's tsmaster 사용기
- Signals 탭에서 Add 버튼을 클릭하여 메시지에 추가할 신호들을 추가할 수 있다. 그렇게 하려면 신호가 먼저 정의되어 있어야 한다. 신호를 정의하는 방법은 아래에서 설명한다.

메시지 정의 창에서 메시지에 포함될 신호들을 추가하는 탭이다. - 신호를 삭제(Remove 버튼)할 수도 있다.
- Transmitters 탭에서 Add 버튼을 클릭하여 메시지를 전송하는 제어기"들"을 추가할 수 있다. 동일한 메시지를 여러 제어기들이 전송할 수도 있다. (Transmitter"s" 이다.) 제어기를 삭제(Remove 버튼)할 수도 있다.
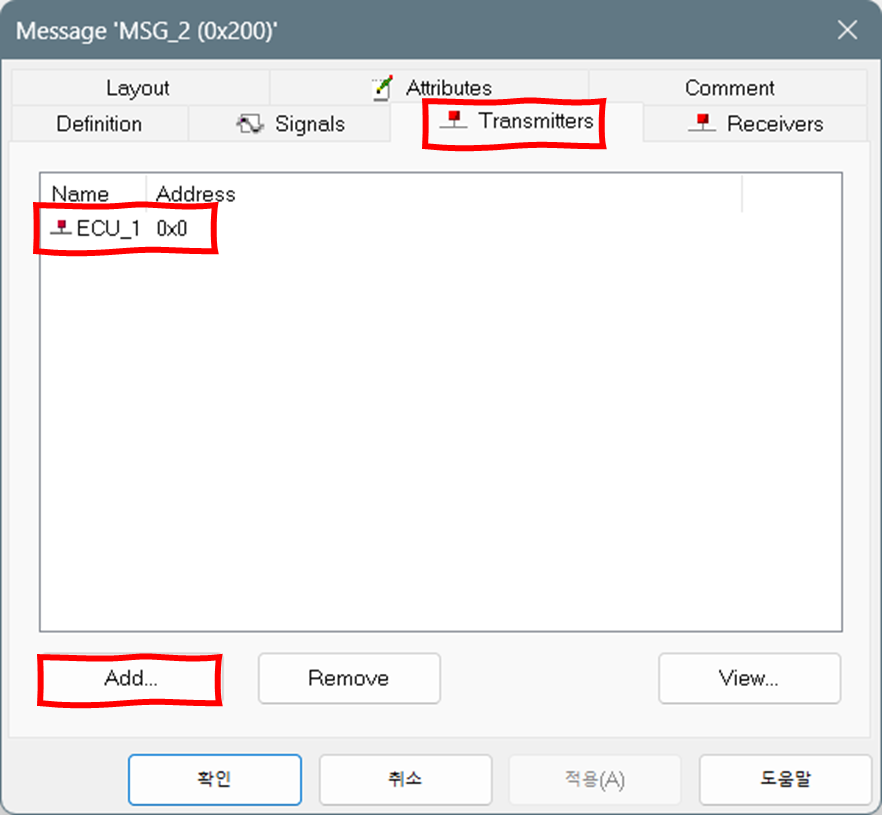
Transmitter"s" 탭에서 전송 제어기"들"을 추가할 수 있다. - Receivers 탭에는 수신 제어기를 추가, 삭제할 수 있는 Add나 Remove 버튼이 없다. 수신 제어기는 "신호별로" 정한다. 따라서 신호를 정의하는 창에서 수신 제어기들을 추가, 삭제한다. 메시지 정의 창에서는 수신 제어기들을 표시하기만 한다.
- Layout 탭에서 신호들을 메시지에 배치할 수 있다. 신호의 길이와 바이트 오더는 신호 정의 창에서 사전에 정의해야 한다. (바이트 오더 관련하여 dbc 파일에서 바이트 오더와 스타트 비트 위치와 LSB :: hsl's tsmaster 사용기를 참조하십시오.) 메시지 정의창에서는 스타트 비트를 정하는 셈이다.

신호들의 위치를 정할 수 있다. 겹침이나 빈 비트를 시각적으로 알 수 있어서 좋다. - Comment 탭에서 커멘트를 입력할 수 있다. 신호 정의만으로 충분히 설명할 수 없는 내용을 전달할 수 있어서 좋다. 한글 입력이 가능하나 간혹 불편함이 발생한다. (인코딩과 관련이 있는 것으로 추측한다. 인코딩 관련 설명은 dbc 파일 인코딩 (encoding) :: hsl's tsmaster 사용기를 참조해 주십시오.)

커멘트 창에 한글 입력이 가능하다. 한글이 포함된 dbc를 xlsx로 변환할 경우, 인코딩 EUC-KR로 하지 않으면 xlsx에서 한글이 깨져서 표시된다. 신호 정의에 필요한 데이터는 무엇인가?
- CANdb++ GUI에서 신호를 정의할 때 필요한 항목들을 알 수 있다. 아래 그림은 CANdb++에서 신호를 더블 클릭하면 열리는 신호 설정창이다.

신호 설정에 필요한 데이터들이다. - 각 데이터 항목에 대해서 위에서 설명을 했다.
- 나는 Messages 탭과 Receivers 탭을 제대로 이해하지 못한다.
- CAN은 한 신호에 여러 수신 제어기들이 있다. Receivers 탭에 Add와 Remove 버튼이 있어서, 이 버튼들을 이용하여 수신 제어기들을 추가, 삭제할 수 있어야할 것 같은데 ... 두 버튼들이 없다.
- 사용자는 메시지 설정창에서 메시지에 포함되는 신호들을 추가, 삭제한다. 그렇기 때문에 신호 설정창의 Messages 탭에서는 메시지와 신호의 포함 관계만 표시되면 될 것 같다. 없어도 될 것 같은 Add, Remove 버튼이 존재한다.

신호 설정창의 Receivers 탭과 Messages 탭은 나로서는 잘 이해가 안 된다. dbc2xlsx
- 메시지와 신호를 정의하는데 필요한 신호들을 확인했다. 의도한 사용 케이스가 H사의 xlsx 포맷이기에 처음부터 답은 정해져 있었다.
- dbc를 H사의 xlsx 양식으로 변경하는 코드와 예제 dbc 파일과 변환한 xlsx는 첨부와 같다.
- dbc를 읽어오기 위해서 cantools라는 파이썬 모듈을 사용했다. cantools는 db(database)를 만든다.
- db를 xlsx로 저장하기 위해서 pandas라는 파이썬 모듈을 사용했다. pandas는 df(dataframe)을 만든다. df는 (dbc2xlsx 문맥에서는) 엑셀 표이다.
- db를 df로 변경할 때, 바이트 오더가 big endian 이라면 스타트 비트 표시 방법을 변환한다.
- pandas로 df를 xlsx로 저장할 때, 컬럼 폭이나 행의 배경색 등 포맷을 지정할 수 없다. 일단 pandas에서 xlsx 파일로 저장하고, openpyxl이라는 파이썬 모듈을 사용하여 저장된 xlsx을 다시 읽어서 포맷을 지정한 후 다시 xlsx 파일로 저장하도록 하였다.
- 대부분의 주석은 ai에게 코딩을 하도록 하기 위한 목적이다. :-) 주석을 달면 깃헙 코파일럿이 (정확히는 ChatGPT4.1)이 코드를 제안 했다. 나는 실행해보고 원하는 대로 동작하지 않으면 코드를 수정하거나 주석을 수정하는 방식을 반복하여 스크립트를 마무리했다.
- 이 스크립트는 개념을 설명하기 위한 목적이다. 실제 툴로 사용하기에는 부족하다. 일부 예외는 처리하지만, 대부분 예외에서 스크립트가 종료된다. 사용자의 입력 데이터가 워낙 다양할 수 있다. 스크립트는 정해진 입력만 처리한다.
dbc2xlsx.py0.01MBexample.dbc0.00MBexample.xlsx0.01MB# -*- coding: utf-8 -*- # dbc2xlsx # - H사는 dbc를 xlsx로 관리한다고 한다. # - H사는 dbc의 복잡한 기능/설정(container/contained message)을 사용하지 않는 것 같다. # - dbc를 xlsx로 변환한다. import sys import argparse from pathlib import Path import pandas as pd import cantools from cantools.database.conversion import LinearConversion from collections import OrderedDict from openpyxl import load_workbook from openpyxl.styles import Alignment, PatternFill from openpyxl.utils import get_column_letter def convert_msb_of_big_endian_to_lsb_of_big_endian(signal): ''' cantools의 경우, byte_order가 big_endian이면 signal.start에 MSB 위치가 저장된다. little_endian이면 signal.start에는 LSB 위치가 저장된다. CANdb++는 byte_order와 무관하게 signal.start에 LSB 위치가 저장된다. cantools에서 dbc를 db로 읽을 때, 위 변환이 이미 이뤄진다. xlsx에는 CANdb++의 형식이 사용된다. db를 xlsx로 변환할 때, 위 변환의 역변환을 한다. ''' if signal.byte_order == 'big_endian': start_bit_msb = int(signal.start) start_bit_lsb = start_bit_msb + 7 - 2 * (start_bit_msb % 8) start_bit_lsb += int(signal.length) - 1 start_bit_lsb += 7 - 2 * (start_bit_lsb % 8) return start_bit_lsb else: return signal.start def show_messages_signals(db): ''' 화면에 메시지와 신호 정보를 출력한다. ''' for message in db.messages: print(f"Message: {message.name}") print(f" ID: {hex(message.frame_id)}") print(f" DLC [byte]: {message.length}") print(f" Cycle time [ms]: {message.cycle_time}") for signal in message.signals: print(f" Signal: {signal.name}") print(f" Length [bit]: {signal.length}") print(f" Byte order: {signal.byte_order}") print(f" Start Bit: {signal.start}") print(f" Start Bit (LSB): {convert_msb_of_big_endian_to_lsb_of_big_endian(signal)}") # Value Type if signal.conversion.is_float: if signal.length == 32: print(" Var_Type: Float") else: print(" Var_Type: Double") else: if signal.is_signed: print(" Var_Type: Signed") else: print(" Var_Type: Unsigned") print(f" Initial Value: {signal.initial}") print(f" Factor: {signal.conversion.scale}") print(f" Offset: {signal.conversion.offset}") print(f" Minimum: {signal.minimum}") print(f" Maximum: {signal.maximum}") print(f" Unit: {signal.unit}") # print(f" Unit: {signal.unit}".encode('EUC-KR', errors='replace').decode('EUC-KR')) # Value Table if signal.conversion.choices is None: print(" Value Table: None") elif type(signal.conversion.choices) is OrderedDict: try: print(f" Value Table: {', '.join([f'{k}: {v}' for k, v in signal.conversion.choices.items()])}") # print(f" Value Table: {', '.join([f'{k}: {v}'.encode('EUC-KR', errors='replace').decode('EUC-KR') for k, v in signal.conversion.choices.items()])}") except Exception as e: print(f" Exception with Value Table: {e}") elif type(signal.conversion.choices) is list: print(f" Value Table: {', '.join(signal.conversion.choices)}") try: print(f" Comment: {signal.comment}") print(f" Comments: {signal.comments}") # print(f" Comment: {signal.comment}".encode('EUC-KR', errors='replace').decode('EUC-KR')) # print(f" Comments: {signal.comments}".encode('EUC-KR', errors='replace').decode('EUC-KR')) except Exception as e: print(f" Exception with Comment/Comments: {e}") senders = [sender for sender in message.senders] print(f" Senders: {', '.join(senders)}") receivers = [receiver for receiver in signal.receivers] print(f" Receivers: {', '.join(receivers)}") print() def convert_dbc_to_df(db): ''' cantools의 db를 pandas의 df(DataFrame)로 변환한다. ''' # df에 추가할 데이터 리스트 messages = [] ids = [] dlcs = [] cycle_times = [] signals = [] start_bits = [] signal_lengths = [] byte_orders = [] value_types = [] initial_values = [] factors = [] offsets = [] minimums = [] maximums = [] units = [] value_tables = [] comments = [] senders_list = [] receivers_list = [] # 메시지와 신호 정보를 df에 추가 for message in db.messages: for signal in message.signals: messages.append(message.name) ids.append(hex(message.frame_id)) dlcs.append(message.length) cycle_times.append(message.cycle_time) signals.append(signal.name) # H사는 byte_order를 LSB, MSB로 표시한다. byte_orders.append('MSB' if signal.byte_order == 'big_endian' else 'LSB') # byte_orders.append('Motorola' if signal.byte_order == 'big_endian' else 'Intel') start_bits.append(convert_msb_of_big_endian_to_lsb_of_big_endian(signal)) signal_lengths.append(signal.length) # Value Type if signal.conversion.is_float: if signal.length == 32: value_types.append("Float") else: value_types.append("Double") else: if signal.is_signed: value_types.append("Signed") else: value_types.append("Unsigned") initial_values.append(signal.initial) factors.append(signal.conversion.scale) offsets.append(signal.conversion.offset) minimums.append(signal.minimum) maximums.append(signal.maximum) units.append(signal.unit if signal.unit else None) if signal.conversion.choices is None: value_tables.append('') elif type(signal.conversion.choices) is OrderedDict: value_tables.append('\n'.join([f"{k}: {v};" for k, v in signal.conversion.choices.items()])) elif type(signal.conversion.choices) is list: value_tables.append('\n'.join([item for item in signal.conversion.choices])) else: value_tables.append('') print(f"Unknown value table format: {signal.conversion.choices = } {type(signal.conversion.choices) = }") comments.append(signal.comment if signal.comment else None) senders = [sender for sender in message.senders] if len(senders) == 0: senders_list.append('') else: senders_list.append(', '.join(senders)) receivers = [receiver for receiver in signal.receivers] if len(receivers) == 0: receivers_list.append('') else: receivers_list.append(', '.join(receivers)) # list들의 길이가 모두 같은지 확인한다. lengths = [len(lst) for lst in [messages, ids, dlcs, cycle_times, signals, start_bits, signal_lengths, byte_orders, value_types, initial_values, factors, offsets, minimums, maximums, units, value_tables, comments, senders_list, receivers_list]] if not all(length == lengths[0] for length in lengths): print("messages, ids, dlcs, cycle_times, signals, start_bits, signal_lengths, byte_orders, value_types, initial_values, factors, offsets, minimums, maximums, units, value_tables, comments, senders_list, receivers_list") print(f'{lengths = }') print("Error: All lists must have the same length.") return None # df 생성 df = pd.DataFrame({ 'Message': messages, 'ID': ids, 'DLC [byte]': dlcs, 'Cycle Time [ms]': cycle_times, 'Signal': signals, 'Start Bit': start_bits, 'Length [bit]': signal_lengths, 'Byte Order': byte_orders, 'Value Type': value_types, 'Initial Value': initial_values, 'Factor': factors, 'Offset': offsets, 'Minimum': minimums, 'Maximum': maximums, 'Unit': units, 'Value Table': value_tables, 'Comment': comments, 'Senders': senders_list, 'Receivers': receivers_list }) # df를 ID와 Start Bit으로 정렬한다. df.sort_values(by=['Message', 'Start Bit'], inplace=True) # xlsx에 Sender와 Receiver를 표시하는 표가 있다. # 전체 Senders를 구한다. # 전체 Receivers를 구한다. senders_set = set() receivers_set = set() for message in db.messages: for sender in message.senders: senders_set.add(sender) for signal in message.signals: for receiver in signal.receivers: receivers_set.add(receiver) # 전체 ECUs 리스트를 생성한다. ecus_set = senders_set.union(receivers_set) ecus_list = list(ecus_set) ecus_list.sort() # df에 ecus_list의 ECU들을 컬럼으로 추가한다. df_ecus = pd.DataFrame('', index=range(len(df)), columns=ecus_list) df = pd.concat([df, df_ecus], axis=1) # df의 각 행에 대해 아래 작업을 수행한다. # Senders 컬럼의 스트링을 ',' 로 분리하고 strip()하여 리스트로 만든다. 리스트의 원소는 ECU 이름이다. # df의 ECU 이름 컬럼에 해당하는 현재 행의 셀 찾아서 'T' 값을 입력한다. # Receivers 컬럼에 대해서도 같은 작업을 수행한다. 단, 셀에 'R' 값을 입력한다. for index, row in df.iterrows(): receivers = row['Receivers'].split(',') # Receivers 컬럼의 스트링을 ','로 분리 receivers = [r.strip() for r in receivers] # 각 원소의 앞뒤 공백 제거 for r in receivers: if r in df.columns: df.at[index, r] = 'R' # 해당 ECU 이름의 셀에 'R' 입력 senders = row['Senders'].split(',') # Senders 컬럼의 스트링을 ','로 분리 senders = [s.strip() for s in senders] # 각 원소의 앞뒤 공백 제거 for s in senders: if s in df.columns: df.at[index, s] = 'T' # 해당 ECU 이름의 셀에 'T' 입력 # 컬럼 Senders와 Receivers 삭제한다. df = df.drop(columns=['Senders', 'Receivers']) return df def save_df_to_xlsx(df, xlsx_output): ''' df를 xlsx로 저장한다. pandas에서 df를 xlsx로 저장할 때는 컬럼/셀의 포맷을 지정할 수 없다. 그래서 일단 pandas에서 df를 xlsx로 저장 후에, openpyxl로 xlsx를 불러와서 포맷을 지정한 후 다시 xlsx로 저장한다. ''' # df를 xlsx로 저장한다. try: with pd.ExcelWriter(xlsx_output, engine='openpyxl') as writer: df.to_excel(writer, sheet_name='CAN matrix', index=False) except Exception as e: print(f"Error saving to Excel: {e}") return 1 # 워크북/시트 불러온다. wb = load_workbook(xlsx_output) ws = wb.active # 맨 위에 빈 행 추가한다. ws.insert_rows(1) # 컬럼 헤더 스타일을 지정한다. (두 번째 행) header_row = 2 gray_fill = PatternFill(start_color='CCCCCC', end_color='CCCCCC', fill_type='solid') for cell in ws[header_row]: cell.alignment = Alignment(textRotation=90, vertical='bottom', horizontal='center') cell.fill = gray_fill # Sender/Receiver 셀 배경색을 지정한다. yellow_fill = PatternFill(start_color='FFFF00', end_color='FFFF00', fill_type='solid') green_fill = PatternFill(start_color='00FF00', end_color='00FF00', fill_type='solid') for row in ws.iter_rows(min_row=header_row+1): for cell in row: if cell.value == "T": cell.fill = yellow_fill elif cell.value == "R": cell.fill = green_fill # 컬럼폭을 조정한다. for col in ws.columns: max_length = 0 col_letter = get_column_letter(col[0].column) for cell in col: try: if cell.value: # 셀의 길이를 측정한다. 최대 길이를 40으로 제한한다. max_length = min(max(max_length, len(str(cell.value))), 40) except: print(f"Error processing cell in column {col_letter}: {cell.value}") ws.column_dimensions[col_letter].width = max_length + 2 # 저장한다. wb.save(xlsx_output) return 0 if __name__ == "__main__": parser = argparse.ArgumentParser(description="Convert DBC to XLSX.") parser.add_argument('-i', '--input_file', type=str, required=True, help='Path to input DBC file') parser.add_argument('-o', '--output_file', type=str, required=False, help='Path to output XLSX file') parser.add_argument('-v', '--verbose', action='store_true', help='Show messages and signals') args = parser.parse_args() # dbc 파일을 읽어온다. dbc_input = Path(args.input_file) db = cantools.database.load_file(dbc_input, encoding='EUC-KR') if args.verbose: show_messages_signals(db) df = convert_dbc_to_df(db) if df is None: print("conversion failed - DataFrame is None") sys.exit(1) if args.output_file: xlsx_output = Path(args.output_file) else: xlsx_output = dbc_input.with_suffix('.xlsx') if save_df_to_xlsx(df, xlsx_output): print("conversion failed - save_df_to_xlsx() returned non-zero") print('같은 이름의 xlsx 파일이 열려있는지 확인하세요.') # 변환이 완료되면 xlsx가 자동으로 열리도록 한다. else: try: import os os.startfile(xlsx_output) except Exception as e: print(f"Error opening file: {e}")결론
- dbc를 H사의 xlsx 형식으로 저장하는 파이썬 스크립트를 작성했다.
- 메시지와 신호를 정의하는 데이터 항목들을 설명하였다. 더 많은 항목들이 있다. 자주 사용되는 항목들만 설명하였다.
- dbc --> xlsx --> dbc
- xlsx2dbc :: hsl's tsmaster 사용기
- dbc2xlsx :: hsl's tsmaster 사용기 <-- 이 포스트
- dbc 파일에서 바이트 오더와 스타트 비트 위치와 LSB :: hsl's tsmaster 사용기
- dbc 파일 인코딩 (encoding) :: hsl's tsmaster 사용기
'tip' 카테고리의 다른 글
filter_blf.py (0) 2026.06.16 CAN dbc를 CAN-FD dbc로 변환하면서 배운 것 (1) 2025.12.09 dbc 파일에서 바이트 오더와 스타트 비트 위치와 LSB (1) 2025.08.27 dbc 파일 인코딩 (encoding) (3) 2025.08.26 xlsx2dbc (1) 2025.08.22